背景介绍
目前主流卷积神经网络,模型参数巨大。并且计算卷积层和全连接层需要大量的浮点矩阵乘法,导致计算开销也非常大。这样卷积神经网络模型在终端部署和低延迟需求场景下难以应用,必须经过模型压缩和裁剪。一般来说,卷积神经网络模型参数主要来自全连接层,计算开销主要来自卷积层。 以经典的VGG-16网络为例
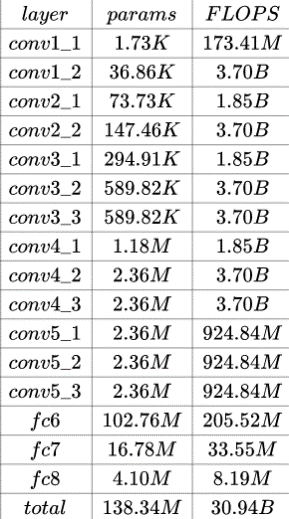
VGG-16_params
其参数数量达到了1亿3千多万,占用超过500MB的磁盘存储空间,需要进行309亿次浮点运算才能完成一张图像的识别任务。如此巨大的存储代价以及计算开销,严重制约了深度网络在移动端等小型设备上的应用。
虽然云计算可以将一部分计算需求转移到云端,但相对于一些高实时性计算场景而言,云计算的带宽、延迟和全时可用性面临着巨大的挑战,从而无法替代本地运算。
许多研究表明,深度神经网络存在过参数化——模型内部参数存在着巨大的冗余。有研究表明[1],只需给定很小一部分的参数子集(大概是全部参数的5%),便能够完整地重构出剩余的参数,从而揭示了模型压缩的可行性。不过这种参数的冗余在模型训练过程中,是十分必要的
除了单纯追求压缩比和精度保证,大部分的模型压缩是能够带来速度的提升——所以模型压缩某种程度而言既包含了体积压缩也包含了时间压缩。当然,加速并不能直接由模型的复杂度(模型大小)所直接决定,还需要考虑计算的时间耗费,所以,有些压缩并不能带来加速效果(参数少不代表运行速度快)。
当然也是有纯粹的模型加速,例如:
模型压缩的分类
根据压缩过程对网络结构的破坏程度,可以将模型压缩技术分为“前端压缩”与“后端压缩”
所谓前端压缩,就是指不改变原有网络结构的压缩技术。其最终模型可以完美适配现有的深度学习框架。
后端压缩则为了极致的压缩比,不得不对网络结构进行改造,并且这种改造往往是不可逆的。同时为了理>想的压缩效果,必须开发配套的运行库,甚至是专门的硬件设备,从而带来了巨大的维护成本。
| 前端压缩 | 后端压缩 |
|---|---|
| 1.知识蒸馏(knowledge distillation) | 1.低秩近似(low-rank factorization) |
| 2.滤波器层面的剪枝(filter-level pruning) | 2.连接层面的剪枝connectivity-level pruning) |
| 3. 轻量化/紧凑的模型结构设计(structured simplification) | 3.参数量化(quantization) |
纯粹的模型加速
为了实现模型加速的目的而使用的各种各样的方法,往往不会考虑到模型复杂度及模型大小等问题。有一定的启发和借鉴作用。