轻量化/紧凑的模型结构设计
相比于在已经训练好的模型上进行处理,轻量化模型模型设计则是另辟蹊径。轻量化模型设计主要思想在于设计更高效的「网络计算方式」(主要针对卷积方式),从而使网络参数减少的同时,不损失网络性能。
相关研究
SqueezeNet
由伯克利&斯坦福的研究人员合作发表于ICLR-2017。
不同于传统的卷积方式,提出Fire Module;Fire Module 包含两部分:Squeeze层和Expand层。
- Squeeze层,就是\(1×1\)卷积,其卷积核数要少于上一层feature map数。
- Expand层,分别用\(1×1\)和\(3×3\)卷积,然后将卷积后的feature map concat起来。
Insight:
- 将大部分的3×3的卷积核使用1×1卷积核进行替换
- 减少进行3×3卷积的输入通道数。 假设卷积层全部由3×3的卷积核构成,那么要减少卷积层的参数,不仅需要减少3×3卷积核的个数, 还需要减少3×3卷积核的输入通道。
- 在网络中晚点进行下采样,这样卷积层能有较大的activation map。在卷积网络中,每个卷积层都会输出一个activation map并且分辨率大小至少为1×1.这个分辨率由(1)输入数据大小(2)是否进行了下采样;所控制。因此,activation map大小对网络的分类准确率至关重要,越大分类准确率越高。推迟下采样能够导致更高的分类准确率。
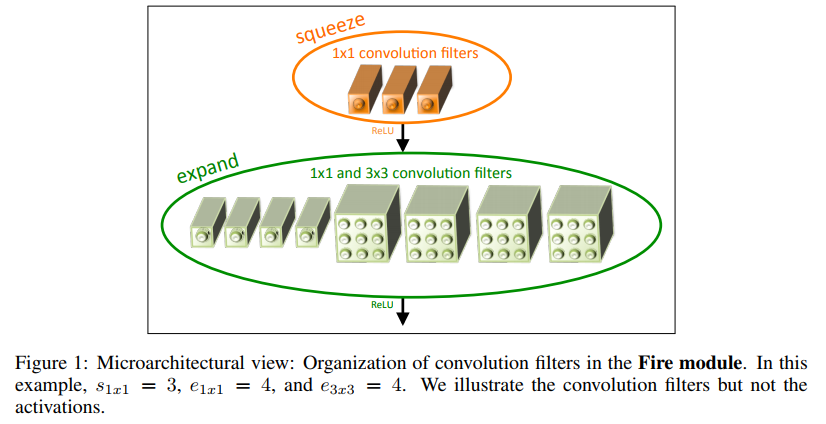
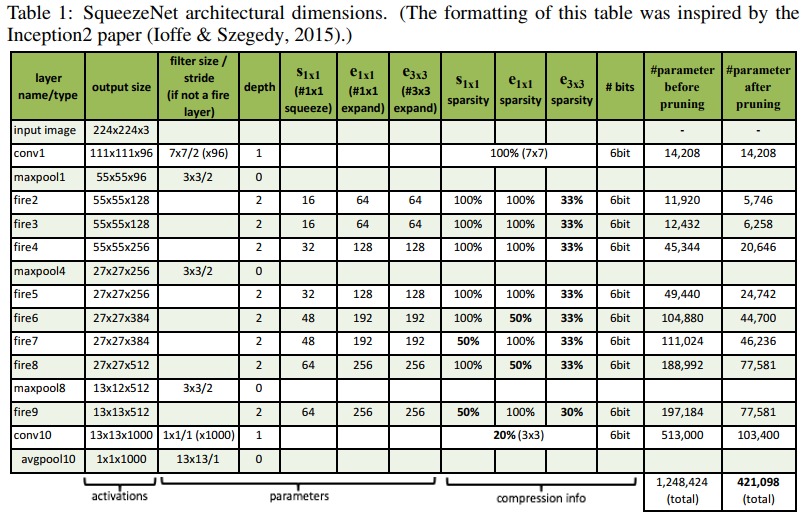
Fire Module有三个超参数:\(s_{1×1}\),\(e_{1×1}\),\(e_{3×3}\),分别代表对应卷积核的个数,同时也表示对应输出feature map的维数,在文中提出的SqueezeNet结构中,\(e_{1×1}+e_{3×3}>s_{1×1}\),这样能够将进行3×3卷积的输入通道数减少。 首先,\(H×W×M\)的feature map经过Squeeze层,得到\(s_{1×1}\)个feature map,这里的\(s_{1×1}\)均是小于\(M\)的,以达到压缩的目的。 其次,\(H×W×s_{1×1}\)的特征图输入到Expand层,分别经过\(1×1\)卷积层和\(3×3\)卷积层进行卷积,再将结果进行 concat,得到Fire module的输出,为\(H×M×(e_{1×1}+e_{3×3})\)的feature map。
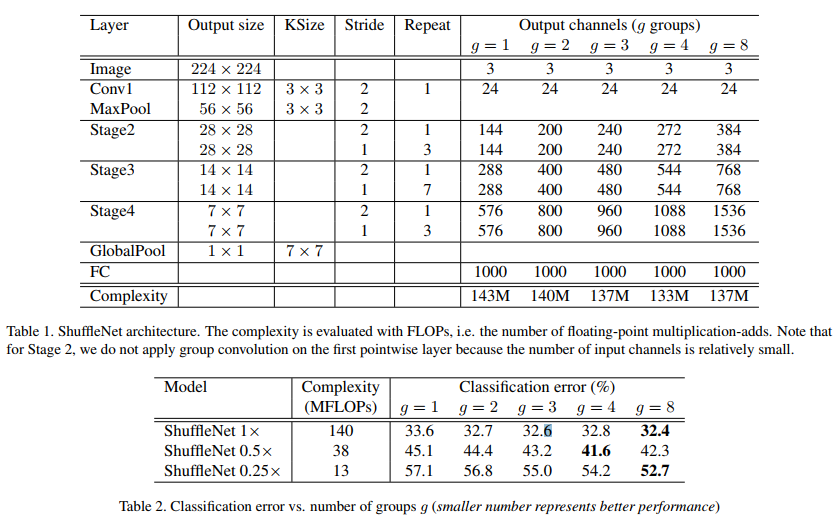
SqueezeNet的网络结构:
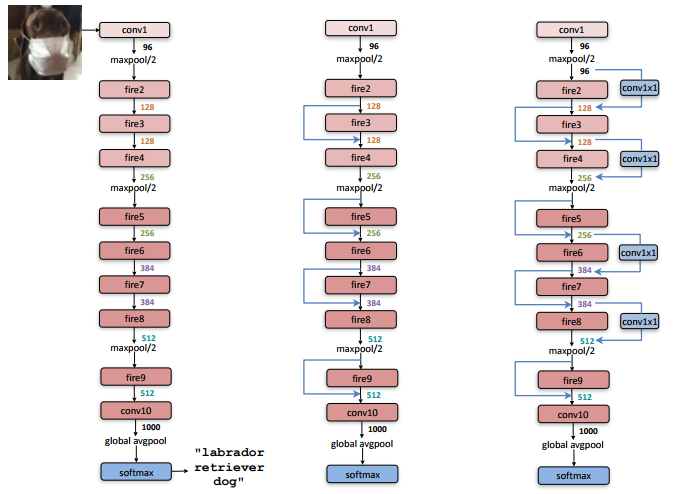
网络结构主要还是使用Fire Module替代传统的卷积层,和VGG一样采用卷积堆叠的方式。
网络结构各层维度:
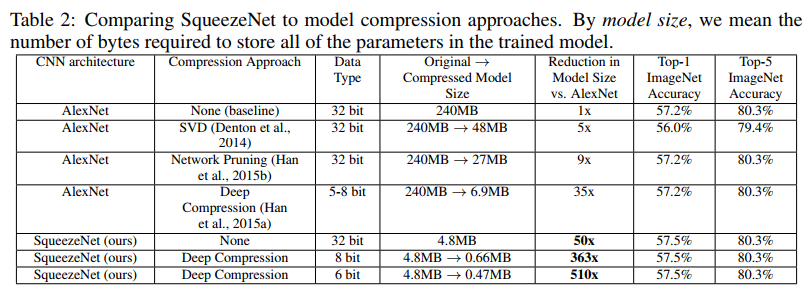
实验结果:
小结:
SqueezeNet 使用Fire Module替代传统的卷积层,由于大量使用了1×1的卷积核,因而权值参数相比传统的网络模型(如AlexNet)要大大减少,在同等准确率表现和无其他压缩算法使用的前提下,SqueezeNet仅需4.8MB的空间来存储,而与之相对应的AlexNet则需要240MB。而最关键的是,还能叠加其他压缩算法,比如使用6bit的Deep Compression,能将模型存储空间压缩至惊人的0.47MB而准确率几无损失。尽管SqueezeNet在压缩上表现惊人,但是在加速上似乎并没有提升。
Xception
MobileNet
由谷歌团队提出,发表于CVPR-2017。
MobileNet顾名思义,是一种能够部署在移动端的网络模型。主要是采用depth-wise separable convolution(下称DWS)的卷积方式(由depth-wise convolution和point-wise convolution构成)替换传统的卷积计算过程。
Insight:
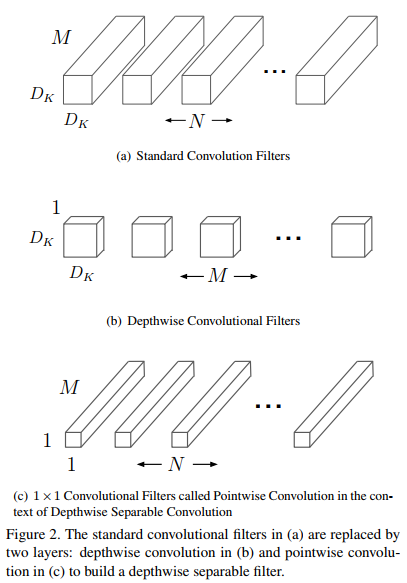
depth-wise convolution(下称DW卷积),最早由2014的L Sifre提出,每个输入通道只被一个卷积核卷积,可以视为特殊的group convolution(每组输入通道只被一组卷积核卷积。[ShuffleNet所使用])
point-wise convolution(下称PW卷积),就是1×1的卷积操作。
C = input channels
N = output feature channels
K = kernel size
H = height of feature map
W = width of feature map传统卷积时间复杂度:\[O_1=O(CNKKHW)\] DWS卷积时间复杂度:\[O_2=O(KKCHW+CNHW)\] 加速比:\[O_2/O_1=1/N + 1/K^2 ≈ 1/K^2\]
MobileNet将传统卷积替换成DWS卷积:
- 进行DW卷积,一个输入通道只被一个卷积核滤波;
- 进行PW卷积,将DW卷积的输出进行线性组合。
使用PW卷积的理由如下:
However it only filters input channels, it does not combine them to create new features. So an additional layer that computes a linear combination of the output of depth-wise convolution via \(1×1\) convolution is needed in order to generate these new features。
从信息流动的角度而言,就是卷积层输出的每个feature map都应当包含输入的所有feature map的全部信息,而DW卷积是无法实现这个操作的,所以还需要PW卷积将DW卷积后的输出的每个feature map串联起来。
MobileNet的网络结构:
DWS卷积结构与传统卷积结构 >
网络结构和每种类型的网络层占整个网络的参数比重和计算比重
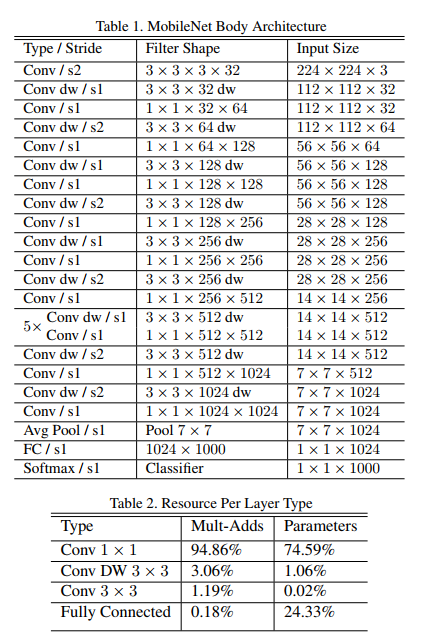
共有28层,其中注意到在MobileNet中除了全连接网络之前使用了Avg Pool以外,其余的下采样并没有使用传统的池化层,而是选择使用步长为2的PW卷积(Conv dw/s2)来实现的。
实验结果:
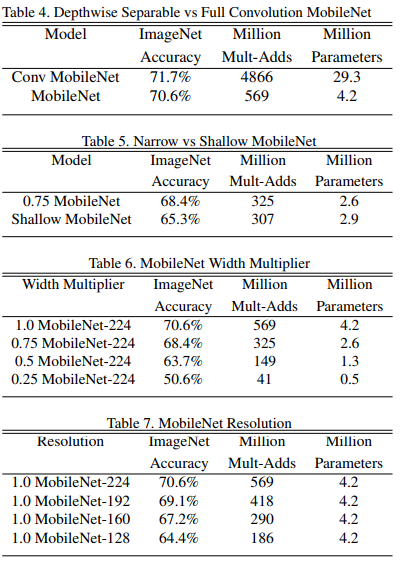
The role of the width multiplier \(α\) is to thin a network uniformly at each layer. For a given layerand width multiplier \(α\), the number of input channels \(M\) becomes \(αM\) and the number of output channels \(N\) becomes αN.
where \(ρ∈(0, 1]\) which is typically set implicitly so that the input resolution of the network is 224, 192, 160 or 128. \(ρ=1\) is the baseline MobileNet and \(ρ<1\) are reduced computation MobileNets. Resolution multiplier has the effect of reducing computational cost by \(ρ^2\).
实验中引入了控制模型收缩程度(输入通道大小)的超参数\(α\)和控制输入图片分辨率大小的超参数\(ρ\),因此计算代价公式更新为:
\[D_K * D_K * αM * ρD_F * ρD_F + αM * αN * ρD_F * ρD_F\]
以下是MobileNet与其他网络模型的对比实验:
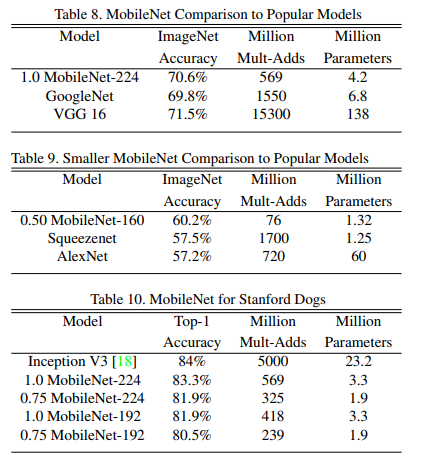
尽管参数上和GoogleNet是一个量级的,但是运算量更少,运算速度更快。
小结:
MobileNet最关键的地方在于采用了DWS卷积方式来替代传统的卷积。为了解决使用DW卷积带来的输入信息无法汇总,MobileNet使用了PW卷积的方法来。最后不仅大大减少了模型参数量,还提升了运算速度。
ShuffleNet
由Face++团队提出,发表于CVPR-2017
ShuffleNet,顾名思义,shuffle是这个网络的精髓,这里的shuffle指代的是channel shuffle,是为了解决采用group convolution带来的输入信息无法汇总的缺点。
Insight:
Group convolution最早由A Krizhevsky等人在2012年提出的,用于将网络模型分布在2个或更多的GPU上计算。主要思路为,一组输入通道只被一组卷积核卷积。
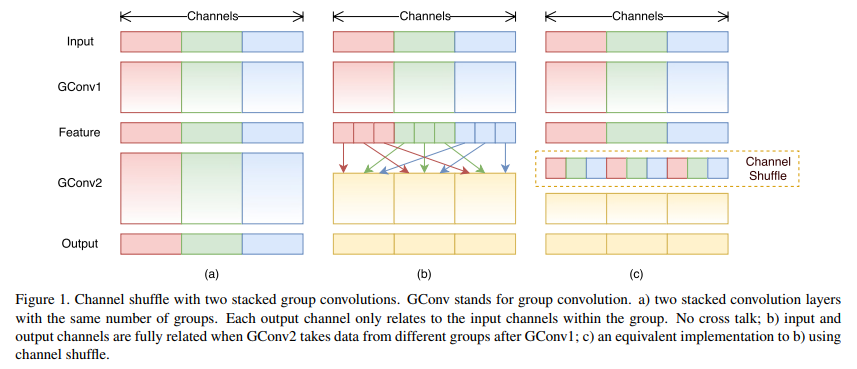
Channel shuffle 将group convolution后的每组的通道平均分为N份subgroup,然后重构成新的feature map。如下图所示,可以将这个shuffle的过程看作是全连接。
文中指出了使用point-wise convolution的缺点:占据了相当大量的multiplication-adds运算。
For example, in ResNeXt only \(3 × 3\) layers are equipped with group convolutions. As a result, for each residual unit in ResNeXt the pointwise convolutions occupy 93.4% multiplication-adds (cardinality = 32 as suggested in ResNeXt). In tiny networks, expensive pointwise convolutions result in limited number of channels to meet the complexity constraint, which might significantly damage the accuracy.
更重要的是,channel shuffle 是可微分的,也就是说它可以嵌入到网络结构中用于端对端训练。
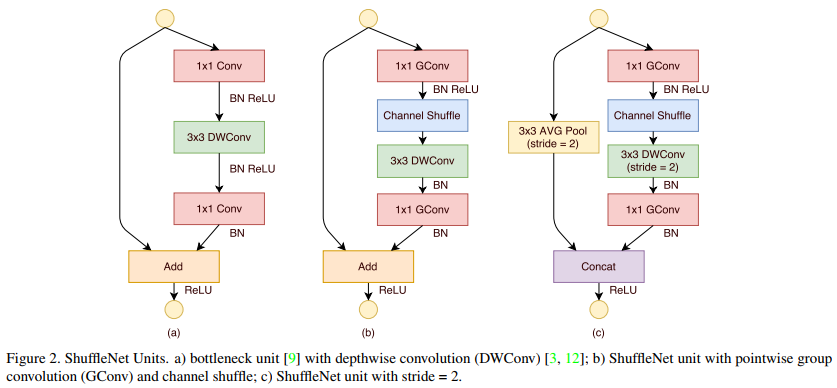
ShuffleNet的基本单元结构,a)是带有DWSConv模块的 bottleneck unit;b)是将PW卷积替换成了\(1×1\) 的group卷积并在第一个group卷积后加入了channel shuffle操作。c)则是在旁路增加了AVG Pool,目的是 为了减少feature map的分辨率大小,然后将DW卷积的stride也设为2.